Материалы по тегу: big data
|
21.05.2026 [00:43], Владимир Мироненко
Postgres Professional представила СУБД Postgres Pro AXE для гибридных нагрузокРоссийский разработчик Postgres Professional объявил о выходе новой СУБД Postgres Pro AXE для аналитических и гибридных нагрузок, которая, как заявляется, позволит компаниям заместить зарубежные аналитические платформы, упростить ИТ-ландшафт и при этом снизить совокупную стоимость владения (TCO) компонентами для хранения и обработки аналитических данных. После ухода с российского рынка ряда западных поставщиков СУБД и прекращения ими поддержки своих решений, включая Oracle Exadata и SAP HANA, отечественные компании столкнулись с усложнением IT-ландшафта и ростом затрат на его эксплуатацию из-за высокой фрагментации, использования разрозненных системам для транзакций и аналитики, проблем с наймом квалифицированных специалистов и т.д., говорит компания. Как сообщает разработчик, Postgres Pro AXE предназначена для выполнения тяжелых аналитических запросов и может использоваться как в качестве аналитической СУБД рядом с уже имеющимися системами, так и в составе уже привычной в эксплуатации Postgres Pro Enterprise. В последнем случае AXE расширяет возможности основной системы аналитической функциональностью на существующих узлах. Это позволяет не разворачивать лишние кластера и не нанимать дополнительный штат администраторов, с наймом которых сейчас наблюдаются проблемы, под узкие аналитические системы. Это также обеспечивает эффективный подход к организации ИТ-стека: уровень надёжности не снижается, но при этом устраняются дублирование инфраструктуры и кратный рост операционных затрат. 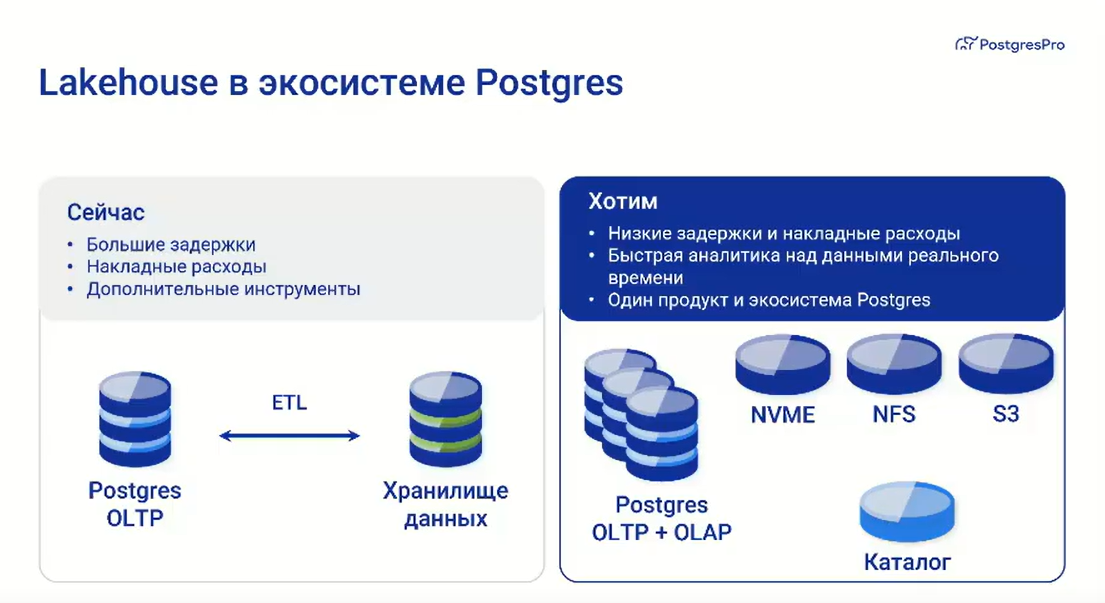
Источник изображения: Postgres Professiona Согласно результатам внутренних испытаний на отраслевых бенчмарках ClickBench, TPC-H и TPC-DS, новое решение обеспечивает:
СУБД поддерживает работу с разными типами хранилищ: от локального сервера до сетевого файлового доступа и S3-хранилищ. Аналитические данные хранятся в формате Parquet, используемом для аналитики больших данных (Big Data) и систем класса Data Lake и Warehouse. Метаданные, определяющие эти данные, также фиксируются по открытой спецификации. В итоге это позволяет работать с любыми BI-инструментами, без привязки к одному поставщику. В настоящее время решение тестируется в пилотном режиме в более чем в десяти организациях в промышленности, сферах финансов, ретейла и телекома. По итогам пилотов заказчики отметили упрощение аналитического контура, ускорение работы с данными и снижение нагрузки на команды эксплуатации. Ряд крупных российских компаний уже выбрал это решение для промышленной эксплуатации. Компания отметила, что вывод Postgres Pro AXE на рынок является частью её долгосрочной стратегии по формированию в России полного импортонезависимого стека для работы с данными. До этого, в прошлом году компания представила платформу Tengri Data для работы со сверхбольшими массивами данных с разделением вычислений и хранения. С выходом нового решения продуктовый портфель компании покрывает весь спектр задач — от транзакционных систем до петабайтных аналитических озёр данных.
27.03.2026 [00:07], Андрей Крупин
VK Tech усилила дата-направление технологиями CedrusDataПоставщик корпоративного программного обеспечения VK Tech (входит в экосистему VK) и разработчик решений для работы с большими данными CedrusData объявили о сотрудничестве. Сделка направлена на развитие и усиление продуктовой линейки VK Tech в области хранения, обработки, анализа данных и систем искусственного интеллекта. VK Tech развивает lakehouse-платформу VK Data Platform на базе S3-совместимого хранилища VK Object Storage и колоночной базы данных Tarantool Column Store. Интеграция CedrusData усилит её за счёт высокопроизводительного массивно-параллельного SQL-движка CedrusData Engine и каталога метаданных CedrusData Catalog с поддержкой открытого табличного формата хранения и обработки больших массивов данных Apache Iceberg. 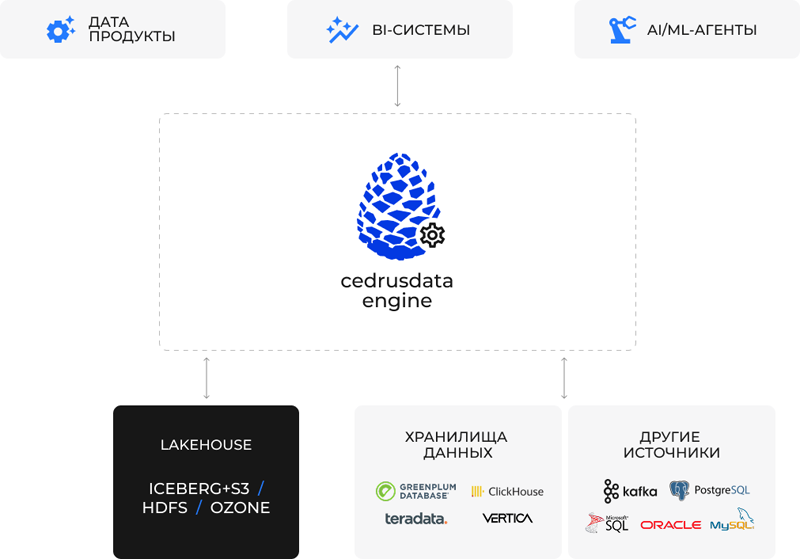
Источник изображения: cedrusdata.ru По словам партнёров, объединённое решение позволит сформировать единый стек хранения/обработки данных и обеспечит взаимодействие с ними без дублирования информации и реализации сложных процессов ETL (Extract, Transform, Load). Такая архитектура позволит клиентам эффективно управлять цифровыми активами любого объёма, обеспечивая мгновенный доступ к аналитике и строгий порядок в структуре хранения как в облаке (On-Cloud), так и в периметре организации (On-Premise). В результате клиенты получат масштабируемую lakehouse-платформу для работы с данными любого объёма с единым управлением, высокой производительностью и готовностью к AI/ML-нагрузкам.
16.10.2025 [13:51], Андрей Крупин
Postgres Professional вышла на рынок аналитических СУБД в России с продуктом Tengri DataКомпания Postgres Professional объявила о выпуске Tengri Data — корпоративной аналитической платформы для работы с большими данными. Решение позволяет обрабатывать данные суммарным объёмом до 10 Пбайт, что открывает крупным организациям доступ к масштабной аналитике без ограничений. В отличие от многих аналогичных продуктов, основанных на Greenplum, платформа Tengri Data разработана на парадигме OpenLakehouse. Она использует принцип разделения вычислений (Compute) и хранилища (Storage), а также хранит данные в объектном хранилище S3, что обеспечивает гибкость, масштабирование и высокую производительность, независимо от нагрузки и количества аналитиков. В свою очередь это позволяет снизить стоимость владения (TCO) и повысить рентабельность инвестиций (ROI). 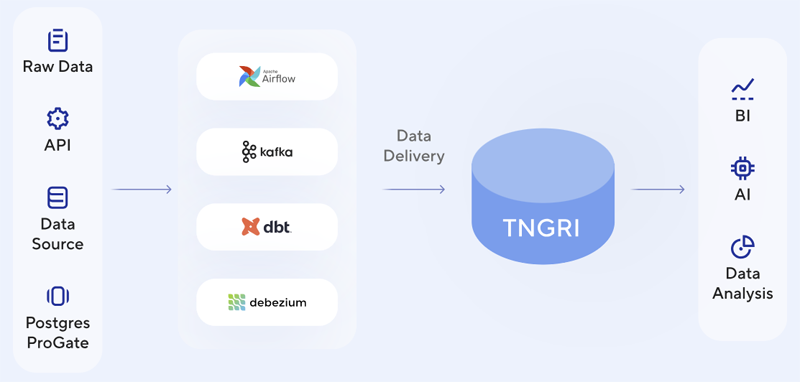
Архитектура платформы Tengri Data (источник изображений: tngri.postgrespro.ru) Tengri Data поддерживает знакомый IT-специалистам стек технологий: язык SQL для трансформации данных, язык Python для скриптования, машинного обучения и искусственного интеллекта, а также стандартные способы подключений. Это позволяет организациям использовать Tengri Data без затрат на переобучение сотрудников или перестройку бизнес-процессов. 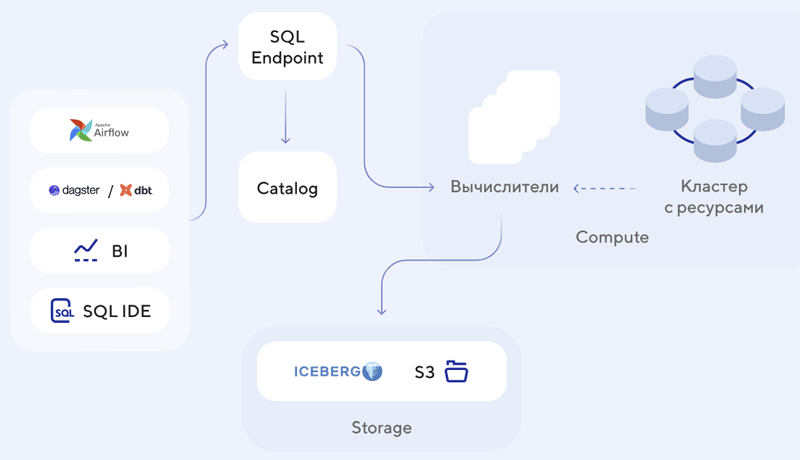
Схема развёртывания Tengri Data «Многие компании в России по-прежнему работают на решениях, созданных на базе Greenplum, который больше не развивается в рамках Open Source. Эти технологии требуют замены и не отвечают современным требованиям и способам аналитической работы с данными, не справляются с ростом объёмов хранилища и числа пользователей. Tengri Data предлагает рынку принципиально иной уровень аналитики, отвечающий запросу на масштабируемую и гибкую платформу», — отмечает Postgres Professional. Рынок платформ для работы с данными рассматривается разработчиком как стратегически перспективный на фоне прогнозируемого стремительного роста: по оценке J’son & Partners Consulting, среднегодовые темпы роста упомянутого сегмента до 2028 года составят свыше 30 % от уровня 2024 года, а потенциальный объем рынка вендорских решений этого класса в РФ оценивается в 10,1 млрд рублей. К 2028 году Postgres Professional планирует занять не менее 50 % объёма рынка лицензий этого сегмента.
21.07.2025 [16:35], Андрей Крупин
MWS Cloud запустила платформу хранения больших данных для обучения ИИКомпания MWS Cloud (входит в МТС Web Services) сообщила о запуске MWS Data Lakehouse — cloud-native-платформы для хранения и обработки данных. MWS Data Lakehouse позволяет работать с любыми типами данных — структурированными, неструктурированными и векторными, что даёт возможность создания единой среды для выполнения разного типа задач: от построения аналитических отчётов до обучения и инференса ML-моделей и LLM. В качестве инфраструктуры для развёртывания платформы могут использоваться различные решения, среди которых Kubernetes и объектное S3-совместимое хранилище. Поддерживается взаимодействие с СУБД Greenplum и Postgres. В MWS Data Lakehouse также встроены инструменты централизации контроля доступа, аудита и шифрования, динамического маскирования чувствительных данных, которые полностью соответствуют современным требованиям информационной безопасности. 
Источник изображения: Luke Peters / unsplash.com В числе особенностей MWS Data Lakehouse — поддержка широкого спектра данных (включая открытые форматы Apache Parquet и Iceberg) и возможность параллельного запуска нескольких вычислительных кластеров под разные продуктовые команды, приложения и типы запросов без дублирования данных и дополнительной репликации. Администрирование сервиса осуществляется через единый интерфейс, позволяющий централизованно управлять пользователями, кластерами и масштабированием. Поддерживается динамическое изменение ресурсов вычислительных кластеров. Платформа является частью комплекса сервисов MWS по работе с данными — MWS Data. Всего в него входят более 25 продуктов для хранения, обработки и трансформации данных, а также сервисы бизнес-аналитики и ИИ-агенты для работы с данными.
01.07.2025 [14:59], Андрей Крупин
МТС Web Services запустила B2B-платформу MWS Data с ИИ-агентами для работы с большими даннымиКомпания МТС Web Services (MWS, входит в группу МТС) сообщила о запуске платформы MWS Data для работы с большими данными. Решение предоставляет целый комплекс инструментов для хранения, обработки, визуализации, контроля качества и безопасности данных и позволяет одновременно управлять данными, полученными в режиме реального времени, и историческими массивами. MWS Data нацелена на крупный и средний бизнес в разных отраслях экономики. Платформа объединяет преимущества хранилищ и озёр данных в единую систему, позволяет хранить и обрабатывать любые типы данных. Особенностью продукта является поддержка технологий машинного обучения и искусственного интеллекта на базе нейронных сетей. В частности, в составе MWS Data представлен ИИ-агент для автоматизации наполнения каталога данных. Также в платформу встроен ИИ-агент для анализа данных по запросу от пользователя на естественном языке. Он преобразует текстовый запрос в SQL-код и формирует отчёт с визуализацией. В результате все категории пользователей за несколько секунд получают доступ к сложной аналитике без привлечения разработчиков. 
Источник изображения: Luke Peters / unsplash.com Утверждается, что использование платформы MWS Data позволит компаниям сократить время обработки информации, повысить точность прогнозных моделей, а также снизить расходы на хранение данных на 40 %. Решение доступно как для развёртывания на инфраструктуре заказчика, так и для использования в облачном окружении MWS.
29.06.2025 [00:20], Сергей Карасёв
Speedata представила ускоритель анализа данных и привлекла на развитие $44 млнСтартап Speedata, занимающийся разработкой специализированных чипов для ускорения аналитики данных, провёл раунд финансирования Series B, в ходе которого на развитие получено $44 млн. В общей сложности на сегодняшний день компания привлекла $114 млн. Speedata разработала аналитический сопроцессор (Analytics Processing Unit, APU) под названием Callisto. Утверждается, что в случае рабочих нагрузок Apache Spark это изделие способно обеспечить 100-кратный прирост производительности по сравнению с CPU. Если сравнивать с GPU, то разработчик обещает сокращение капитальных затрат на 91 %, экономию пространства на 94 % и уменьшение потребления электроэнергии на 86 %. Особенность Callisto — использование относительно новой архитектуры CGRA, в разработке которой принимали участие основатели Speedata. Подобно программируемым пользователем вентильным матрицам (FPGA) решения с архитектурой GCRA можно настроить на выполнение определённых задач с максимальной эффективностью. При этом в случае Callisto устранены ограничения с обработкой логики ветвления, с которыми могут сталкиваться GPU, говорит компания. Кроме того, Callisto содержит ряд других оптимизаций для повышения производительности при аналитике данных. 
Источник изображения: Speedata Чип Callisto является основой серверного ускорителя C200. Это решение выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Новинка обеспечивает ускорение операций, связанных с аналитикой данных на аппаратном уровне, снижая нагрузку на CPU. Speedata обещает «революционное соотношение цены и производительности», а также возможность обработки огромных массивов информации в рекордно короткие сроки. В систему типоразмера 2U могут быть установлены две карты C200. В качестве примера возможностей новинки компания Speedata приводит обработку некой рабочей нагрузки в фармацевтической области. С использованием APU задача была выполнена за 19 минут по сравнению с 90 часами при применении неспециализированного процессора. Таким образом, обеспечено ускорение в 280 раз. В раунде финансирования Series B приняли участие Walden Catalyst Ventures, 83North, Koch Disruptive Technologies, Pitango First и Viola Ventures, а также ряд стратегических инвесторов, в число которых вошли генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) и соучредитель Mellanox Technologies Эяль Вальдман (Eyal Waldman). Деньги будут направлены на дальнейшее развитие технологии.
29.05.2025 [21:06], Андрей Крупин
Yandex B2B Tech запустила YTsaurus — платформу обработки данных любого объёма для бизнесаYandex B2B Tech (бизнес-группа «Яндекса», объединяющая технологии и инструменты компании для корпоративных пользователей, включая продукты Yandex Cloud и «Яндекс 360») открыла доступ к платформе собственной разработки для хранения и обработки больших данных YTsaurus. YTsaurus поставляется как управляемое решение в Yandex Cloud, а также on-premises с поддержкой от разработчиков. Платформа обеспечивает хранение, обработку, аналитику данных и машинное обучение в едином окружении: файловая система, динамические таблицы и аналитические инструменты объединены для полного цикла работы с большими данными. Система поддерживает миллионы CPU и тысячи GPU в рамках единого кластера и десятки тысяч вычислительных узлов. Встроенный HDRF‑планировщик распределяет и балансирует вычислительные ресурсы между задачами пользователей. 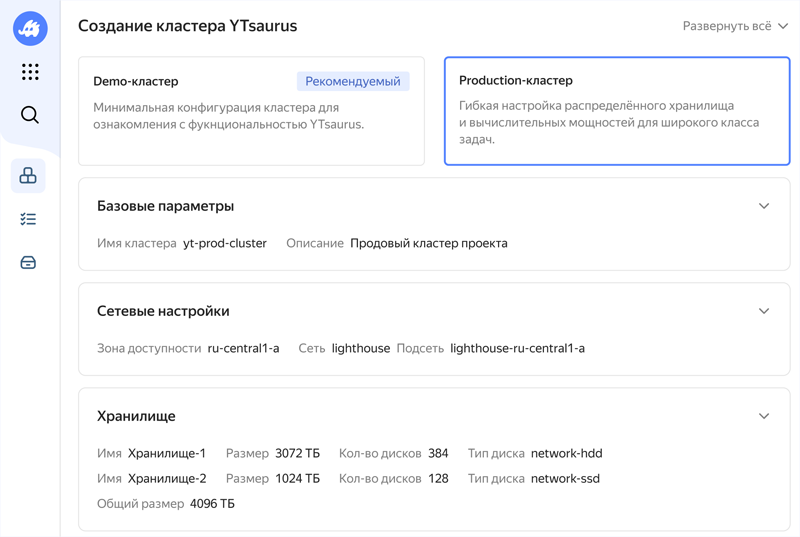
Источник изображения: yandex.cloud YTsaurus можно использовать как классическую MapReduce-систему, так и применять внутри платформы другие востребованные в профессиональной среде решения для обработки данных, в том числе ClickHouse и Apache Spark. C её помощью можно строить корпоративные хранилища данных, ETL-системы, обрабатывать как структурированные, так и неструктурированные или полуструктурированные данные, в том числе логи или финансовые транзакции. В «Яндексе» YTsaurus разрабатывают с 2010 года — сейчас её используют для хранения данных большинства сервисов, обучения YandexGPT и других нейросетей, задач поискового индекса. Ранее платформа была доступна как open source-проект — её уже применяют большие технологические компании в России и за рубежом.
29.04.2025 [12:45], Владимир Мироненко
В Москве создадут «госозеро» обезличенных персональных данных для обучения ИИВ Москве планируют создать собственную информационную систему обезличенных персональных данных для обучения ИИ, пишет Forbes со ссылкой на заявление заместителя руководителя департамента информтехнологий (ДИТ) Москвы Владислава Шишмарева. Согласно подготовленной ДИТ презентации, будущая информационная система формирования региональных составов данных (ИС ФРСД) предназначена для сбора и обезличивания личной информации жителей столицы, которая обрабатывается госорганами и подведомственными организациями правительства Москвы. Оператором системы будет ДИТ Москвы. «Обезличенные данные предполагается использовать для обучения алгоритмов ИИ, их применение в других целях не предусмотрено», — пояснили в ДИТ. Согласно данным портала ai.mos.ru, в настоящее время в столице реализуется около 100 проектов с использованием ИИ на разной стадии реализации. Город располагает 25 наборами данных в таких сферах, как электронное правительство, строительство, экономика, культура и ЖКХ, которыми готов делиться с разработчиками ИИ-решений. Для получения полного доступа к этим наборам достаточно отправить заявку с описанием ИИ-проекта, в котором они будут использоваться. После обезличивания данные будут передавать в «госозеро» данных, которое создаёт Минцифры, или же использовать внутри ИС ФРСД. Использовать их будут как госорганы, так и бизнес для аналитических целей. 
Источник изображения: Gabriel Heinzer/unsplash.com Принятым в 2020 году законом в Москве был введён экспериментальный правовой режим (ЭПР) для стимулирования разработки и тестирования новых сервисов на базе ИИ, в рамках которого компании, участвующие в эксперименте, получили широкие возможности по использованию ИИ, включая доступ к данным граждан, в том числе, изображениям с камер распознавания лиц и обезличенным персональным данным. Согласно закону о создании «госозера», принятому в августе 2024 года, будет создана государственная информационная системы (ГИС), куда компании по запросу должны бесплатно передавать обезличенные персональные данные клиентов и сотрудников. При этом для Москвы в законе сделано исключение в связи с действующим ЭПР. Насколько полезным для бизнеса станет создание столичного «озера» данных будет зависеть от того, на каких условиях будут предоставляться дата-сеты и можно ли будет воспользоваться результатами их обработки, считают эксперты. На данный момент по закону выгрузить из «госозера» ничего нельзя, даже результатов анализа информации. Также высказываются опасения, что даже обезличенные персональные данные могут позволить идентифицировать их владельца.
17.02.2025 [21:08], Андрей Крупин
VK запустила облачный Data Lakehouse для аналитики и обработки данныхЗанимающаяся разработкой корпоративного ПО компания VK Tech (входит в экосистему VK) сообщила о включении в состав облачной платформы VK Cloud стека инструментов для построения Data Lakehouse и с возможностью подключения к объектным хранилищам Cloud Storage, Managed PosgtreSQL, Managed Clickhouse. Data Lakehouse представляет собой новый архитектурный подход к хранению и анализу данных, который сочетает элементы «озёр данных» (Data Lake) и корпоративного хранилища данных (Data Warehouse). Он позволяет снизить нагрузку на системы хранения данных, удешевить хранение неструктурированных данных и эффективно анализировать их за счёт разделения вычислительных узлов и хранилищ данных. Data Lakehouse на платформе VK Cloud построен на базе S3-совместимого объектного хранилища собственной разработки и SQL-движка Cloud Trino, реализованного на базе Kubernetes. Использование доработанных Open Source-компонентов в составе Data Lakehouse позволяет организациям получить современный стек для работы с крупными проектами, с оплатой только за фактически потреблённые ресурсы, без необходимости покупать лицензии. 
Источник изображения: VK Cloud Data Lakehouse доступен для построения как на облачной платформе, так и на собственной инфраструктуре на базе Private Cloud и VK Data Platform. Инфраструктура публичного облака VK Cloud аттестована по требованиям 152-ФЗ (УЗ-1).
13.02.2025 [23:58], Руслан Авдеев
Big Data для Большого Брата: глава Oracle предложил собрать все-все данные американцев и обучить на них сверхмощный «присматривающий» ИИ
big data
llm
oracle
software
база данных
государство
ии
информационная безопасность
конфиденциальность
сша
По словам главы Oracle Ларри Эллисона (Larry Ellison), если правительства хотят, чтобы ИИ повысил качество обслуживания и защиту граждан, то необходимо собрать буквально всю информацию о них, включая даже ДНК, в единой базе, которую и использовать для обучения ИИ, сообщает The Register. Таким мнением Эллисон поделился с бывшим премьер-министром Великобритании Тони Блэром (Tony Blair) на мероприятии World Governments Summit в Дубае. Глава Oracle считает, что вскоре искусственный интеллект изменит жизнь каждого обитателя Земли во всех отношениях. По его мнению, нужно сообщить правительству как можно больше информации. Для этого необходимо свести воедино все национальные данные, включая геопространственные данные, информацию об экономике, электронные медицинские записи, в т.ч. информацию о ДНК, сведения об инфраструктуре и др. Т.е. передать буквально всё, обучить на этом массиве ИИ, а потом задавать ему любые вопросы. Подобный проект первым можно реализовать в США, говорит Эллисон. Результатами, по мнению мультимиллиардера, станет рост качества здравоохранения благодаря персонализации медицинской помощи, возможность прогнозировать урожайность и оптимизировать на этой основе производство продовольствия. Можно будет анализировать качество почв, чтобы дать рекомендации фермерам — где именно вносить удобрения и улучшать орошение и др. По словам Эллисона, когда все данные будут храниться в одном месте, можно будет лучше заботиться о пациентах и населении в целом, управлять всевозможными социальными сервисами и избавиться от мошенничества. 
Источник изображения: ev / Unsplash Конечно, такая система баз данных может стать предшественницей тотальной системы наблюдения — о необходимости чего-то подобного мультимиллиардер говорил ещё в прошлом году, намекая, что реализовать такой проект могла бы именно Oracle. Постоянный надзор за населением в режиме реального времени с анализом данных системами машинного обучения Oracle, по его словам, позволит всем «вести себя наилучшим образом». Oracle уже является крупным правительственным и военным подрядчиком в США и готова помочь другим странам реализовать подобные всеобъемлющие ИИ-проекты. Все данные, конечно, предполагается поместить в одну большую систему за авторством Oracle. Как заявил Эллисон, Oracle уже строит ЦОД ёмкостью 2,2 ГВт и стоимостью $50–$100 млрд. Именно на таких площадках будет учиться «сверхмощный» ИИ. Поскольку такие модели очень дороги, свои собственные клиентам, вероятно, обучать и не придётся, зато такие площадки позволят сделать несколько разных крупных моделей. В мире всего несколько компаний, способных обучать модели такого масштаба. В их числе, конечно, Oracle с собственной инфраструктурой. Компания присоединилась к ИИ-мегапроекту Stargate, реализация которого в течение следующих четырёх лет обойдётся в $500 млрд. |
|

